Documents Classification using Machine Learning¶
Introducing the 20newsgroups dataset¶
The 20 Newsgroups data set is a collection of approximately 20,000 newsgroup documents, partitioned (nearly) evenly across 20 different newsgroups.The 20 newsgroups collection has become a popular data set for experiments in text applications of machine learning techniques, such as text classification and text clustering.
For more information, click this link: 20newsgroups Dataset
Machine learning on the 20newsgroups dataset¶
- Framed as a supervised learning problem: Predict the label (class) of test document
- Famous dataset for machine learning of text classificaton
- Learn more about the 20newsgroups dataset: UCI Machine Learning Repository
# import required modules
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
import matplotlib.pyplot as plt
%matplotlib inline
Loading the 20newsgroups dataset into scikit-learn¶
# import 20 newsgroup dataset
from sklearn.datasets import fetch_20newsgroups
#categories = ['alt.atheism', 'comp.graphics', 'sci.space']
categories = None
data_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'), categories=categories)
data_test = fetch_20newsgroups(subset='test', remove=('headers', 'footers', 'quotes'), categories=categories)
type(data_train)
type(data_test)
print "Train data target labels:",data_train.target
print "Test data target labels:",data_test.target
print "Train data target names:",data_train.target_names
print "Test data target names:",data_test.target_names
print "Total train data:",len(data_train.data)
print "Total test data:",len(data_test.data)
# Train data type
print type(data_train.data)
print type(data_train.target)
# Test data type
print type(data_test.data)
print type(data_test.target)
Requirements for working with data in scikit-learn¶
- Features and response are separate objects
- Features and response should be numeric
- Features and response should be NumPy arrays
- Features and response should have specific shapes
# So, first converting text data into vectors of numerical values using tf-idf to form feature vector
vectorizer = TfidfVectorizer()
data_train_vectors = vectorizer.fit_transform(data_train.data)
data_test_vectors = vectorizer.transform(data_test.data)
# Train data type
print type(data_train_vectors.data)
print type(data_train.target)
# Test data type
print type(data_train_vectors.data)
print type(data_train.target)
# check the shape of the features matrix
print data_train_vectors.shape
# check the shape of the response (single dimension matching the number of observations)
print data_train.target.shape
Train \ Test data¶
# store training feature matrix in "Xtr"
Xtr = data_train_vectors
print "Xtr:\n", Xtr
# store training response vector in "ytr"
ytr = data_train.target
print "ytr:",ytr
# store testing feature matrix in "Xtt"
Xtt = data_test_vectors
print "Xtt:\n", Xtt
# store testing response vector in "ytt"
ytt = data_test.target
print "ytt:",ytt
Different Classification Models¶
Multinomial Naive Bayes (MNB) classification¶
# import the required module from scikit learn
from sklearn.naive_bayes import MultinomialNB
# Implementing classification model- using MultinomialNB
# Instantiate the estimator
clf_MNB = MultinomialNB(alpha=.01)
# Fit the model with data (aka "model training")
clf_MNB.fit(Xtr, ytr)
# Predict the response for a new observation
y_pred = clf_MNB.predict(Xtt)
print "Predicted Class Labels:",y_pred
# Predict the response score for a new observation
y_pred_score_mnb = clf_MNB.predict_proba(Xtt)
print "Predicted Score:\n",y_pred_score_mnb
K-Nearest Neighbors (KNN) classification¶
# import the required module from scikit learn
from sklearn.neighbors import KNeighborsClassifier
# Implementing classification model- using KNeighborsClassifier
# Instantiate the estimator
clf_knn = KNeighborsClassifier(n_neighbors=5)
# Fit the model with data (aka "model training")
clf_knn.fit(Xtr, ytr)
# Predict the response for a new observation
y_pred = clf_knn.predict(Xtt)
print "Predicted Class Labels:",y_pred
# Predict the response score for a new observation
y_pred_score_knn = clf_knn.predict_proba(Xtt)
print "Predicted Score:\n",y_pred_score_knn
Support Vector Machine (SVM) classification¶
# import the required module from scikit learn
from sklearn.svm import LinearSVC
# Implementing classification model- using LinearSVC
# Instantiate the estimator
clf_svc = LinearSVC()
# Fit the model with data (aka "model training")
clf_svc.fit(Xtr, ytr)
# Predict the response for a new observation
y_pred = clf_svc.predict(Xtt)
print "Predicted Class Labels:",y_pred
# Predict the response score for a new observation
y_pred_score_svc = clf_svc.decision_function(Xtt)
print "Predicted Score:\n",y_pred_score_svc
Evaluating & Comparing Machine Learning Models¶
Cross-Validation: K-fold¶
- Measurement of Generalization Performance
- For estimation of variation
- Divide the data into K folds
- For k = 1…K
• Train on K-1 sets leaving the kth set out for validation
• Validate on the kth set and obtain the performance metrics
- For k = 1…K
- Report the average and the variation in the performance
Diagram of 5-fold cross-validation:
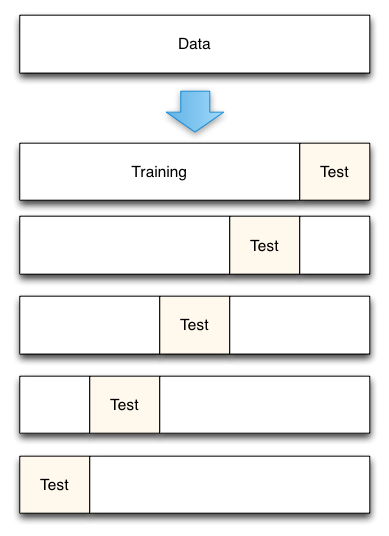
Cross-validation: Model Selection¶
# import the required module
from sklearn.cross_validation import cross_val_score
# 10-fold cross-validation with MNB model
clf_mnb = MultinomialNB(alpha=.01)
print "MultinomialNB 10-Cross Validation Score:",cross_val_score(clf_mnb, Xtr, ytr, cv=10, scoring='accuracy').mean()
# 10-fold cross-validation with KNN model
clf_knn = KNeighborsClassifier(n_neighbors=55)
print "KNN 10-Cross Validation Score:",cross_val_score(clf_knn, Xtr, ytr, cv=10, scoring='accuracy').mean()
# 10-fold cross-validation with Linear SVM model
clf_svc = LinearSVC(C=1)
print "KNN 10-Cross Validation Score:",cross_val_score(clf_svc, Xtr, ytr, cv=10, scoring='accuracy').mean()
Efficiently searching for optimal tuning parameters¶
More efficient parameter tuning using GridSearchCV¶
Allows to define a grid of parameters that will be searched using K-fold cross-validation
# importing the required module
from sklearn.grid_search import GridSearchCV
GridSearchCV for KNN¶
# define the parameter values that should be searched for KNN
k_range = range(1, 100)
weight_options = ['uniform', 'distance']
print k_range
print weight_options
# create a parameter grid: map the parameter names to the values that should be searched for KNN
param_grid = dict(n_neighbors=k_range, weights=weight_options)
print param_grid
# instantiate the grid
grid = GridSearchCV(clf_knn, param_grid, cv=10, scoring='accuracy')
# fit the grid with data
grid.fit(Xtr, ytr)
# view the complete results (list of named tuples)
grid.grid_scores_
# examine the first tuple
print grid.grid_scores_[0].parameters
print grid.grid_scores_[0].cv_validation_scores
print grid.grid_scores_[0].mean_validation_score
# examine the best model
print grid.best_score_
print grid.best_params_
print grid.best_estimator_
Reducing computational expense using RandomizedSearchCV for KNN¶
- Searching many different parameters at once may be computationally infeasible
RandomizedSearchCVsearches a subset of the parameters, and we control the computational "budget"
# importing the required module
from sklearn.grid_search import RandomizedSearchCV
# specify "parameter distributions" rather than a "parameter grid"
param_dist = dict(n_neighbors=k_range, weights=weight_options)
print param_dist
# n_iter controls the number of searches
rand = RandomizedSearchCV(clf_knn, param_dist, cv=10, scoring='accuracy', n_iter=10, random_state=5)
rand.fit(Xtr, ytr)
rand.grid_scores_
# examine the best model
print rand.best_score_
print rand.best_params_
GridSearchCV for Multinomial Naive Bayes¶
# define the parameter values that should be searched for MNB
alpha = [0.001, 0.01, 0.1, 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
print alpha
# create a parameter grid: map the parameter names to the values that should be searched for MNB
param_grid = dict(alpha=alpha)
print param_grid
# instantiate the grid
grid = GridSearchCV(clf_mnb, param_grid, cv=10, scoring='accuracy')
# fit the grid with data
grid.fit(Xtr, ytr)
# view the complete results (list of named tuples)
grid.grid_scores_
# examine the first tuple
print grid.grid_scores_[0].parameters
print grid.grid_scores_[0].cv_validation_scores
print grid.grid_scores_[0].mean_validation_score
# examine the best model
print grid.best_score_
print grid.best_params_
print grid.best_estimator_
GridSearchCV for Linear SVM¶
# define the parameter values that should be searched for Linear SVM
C = range(1,100,10)
tol = [1e-2, 1e-4, 1e-9]
print "C:", C
print "Tolerance for stopping criteria:", tol
# create a parameter grid: map the parameter names to the values that should be searched for SVM
param_grid = dict(C=C, tol=tol)
print param_grid
# instantiate the grid
grid = GridSearchCV(clf_svc, param_grid, cv=10, scoring='accuracy')
# fit the grid with data
grid.fit(Xtr, ytr)
# view the complete results (list of named tuples)
grid.grid_scores_
# examine the first tuple
print grid.grid_scores_[0].parameters
print grid.grid_scores_[0].cv_validation_scores
print grid.grid_scores_[0].mean_validation_score
# examine the best model
print grid.best_score_
print grid.best_params_
print grid.best_estimator_
Reducing computational expense using RandomizedSearchCV for SVM¶
# specify "parameter distributions" rather than a "parameter grid"
param_dist = dict(C=C, tol=tol)
print param_dist
# n_iter controls the number of searches
rand = RandomizedSearchCV(clf_svc, param_dist, cv=10, scoring='accuracy', n_iter=10, random_state=5)
rand.fit(Xtr, ytr)
rand.grid_scores_
# examine the best model
print rand.best_score_
print rand.best_params_
Classification Accuracy¶
- percentage of correct predictions
# importing the required module
from sklearn import metrics
Classification Accuracy of MultinomialNB¶
# Instantiate the estimator
clf_MNB = MultinomialNB(alpha=.01)
# Fit the model with data (aka "model training")
clf_MNB.fit(Xtr, ytr)
# Predict the response for a new observation
y_pred_mnb = clf_MNB.predict(Xtt)
print "Predicted Class Labels:",y_pred_mnb
# calculate accuracy
print "Classification Accuracy:",metrics.accuracy_score(ytt, y_pred_mnb)
Classification Accuracy of KNN¶
# Instantiate the estimator
clf_knn = KNeighborsClassifier(n_neighbors=1, weight='distance')
# Fit the model with data (aka "model training")
clf_knn.fit(Xtr, ytr)
# Predict the response for a new observation
y_pred_knn = clf_knn.predict(Xtt)
print "Predicted Class Labels:",y_pred_knn
# calculate accuracy
print "Classification Accuracy:",metrics.accuracy_score(ytt, y_pred_knn)
Classification Accuracy of Linear SVM¶
# Instantiate the estimator
clf_svc = LinearSVC(C=1, tol=0.01)
# Fit the model with data (aka "model training")
clf_svc.fit(Xtr, ytr)
# Predict the response for a new observation
y_pred_svc = clf_svc.predict(Xtt)
print "Predicted Class Labels:",y_pred_svc
# calculate accuracy
print "Classification Accuracy:",metrics.accuracy_score(ytt, y_pred_svc)
Confusion matrix¶
- Table that describes the performance of a classification model
Confusion matrix of MultinomialNB¶
# first argument is true values, second argument is predicted values
print metrics.confusion_matrix(ytt, y_pred_mnb)
Confusion matrix of KNN¶
# first argument is true values, second argument is predicted values
print metrics.confusion_matrix(ytt, y_pred_knn)
Confusion matrix of Linear SVM¶
# first argument is true values, second argument is predicted values
print metrics.confusion_matrix(ytt, y_pred_svc)
Metrics computed from a confusion matrix¶
Classification Error: Overall, how often is the classifier incorrect?
- Also known as "Misclassification Rate"
print "Classification Error of MultinomialNB:", 1 - metrics.accuracy_score(ytt, y_pred_mnb)
print "Classification Error of KNN:", 1 - metrics.accuracy_score(ytt, y_pred_knn)
print "Classification Error of LinearSVC:", 1 - metrics.accuracy_score(ytt, y_pred_svc)
Sensitivity: When the actual value is positive, how often is the prediction correct?
- How "sensitive" is the classifier to detecting positive instances?
- Also known as "True Positive Rate" or "Recall"
print "Sensitivity of MultinomialNB:",metrics.recall_score(ytt, y_pred_mnb, average='weighted')
print "Sensitivity of KNN:",metrics.recall_score(ytt, y_pred_knn, average='weighted')
print "Sensitivity of LinearSVC:",metrics.recall_score(ytt, y_pred_svc, average='weighted')
Precision: When a positive value is predicted, how often is the prediction correct?
- How "precise" is the classifier when predicting positive instances?
- TP / (TP + FP)
print "Precision of MultinomialNB:", metrics.precision_score(ytt, y_pred_mnb, average='weighted')
print "Precision of KNN:", metrics.precision_score(ytt, y_pred_knn, average='weighted')
print "Precision of LinearSVC:", metrics.precision_score(ytt, y_pred_svc, average='weighted')
F-measure:
- 2 P R / (P + R)
print "F-measure of MultinomialNB:", metrics.f1_score(ytt, y_pred_mnb, average='weighted')
print "F-measure of KNN:", metrics.f1_score(ytt, y_pred_knn, average='weighted')
print "F-measure of LinearSVC:", metrics.f1_score(ytt, y_pred_svc, average='weighted')
Specificity: When the actual value is negative, how often is the prediction correct?
- How "specific" (or "selective") is the classifier in predicting positive instances?
- TN / (TN + FP)
False Positive Rate: When the actual value is negative, how often is the prediction incorrect?
- FP / (TN + FP)
True Positive Rate: When the actual value is positive, how often is the prediction correct?
- TP / (TP + FP)
ROC Curves and Area Under the Curve (AUC)¶
# importing the required modules
from sklearn.metrics import roc_curve, auc
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
def ROC_multi_class(Xtr, ytr, Xtt, ytt, clf):
classes = [0,1, 2, 3, 4]
# Binarize the output
ytr = label_binarize(ytr, classes=classes)
n_classes = ytr.shape[1]
# Learn to predict each class against the other
classifier = OneVsRestClassifier(clf)
classifier.fit(Xtr, ytr)
if (clf == clf_svc):
y_pred_score = classifier.decision_function(Xtt)
else:
y_pred_score = classifier.predict_proba(Xtt)
ytt = label_binarize(ytt, classes=classes)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(ytt[:, i], y_pred_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Plot ROC curves for the multiclass
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i+1, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC of multi-class')
plt.legend(loc="lower right")
plt.show()
Multi-class ROC of Multinomial Naive Bayes¶
# ROC for MultinomialNB
print "ROC and AUC of MultinomialNB"
ROC_multi_class(Xtr, ytr, Xtt, ytt, clf_MNB)

# ROC for KNeighborsClassifier
print "ROC and AUC of KNN"
ROC_multi_class(Xtr, ytr, Xtt, ytt, clf_knn)

# ROC for LinearSVC
print "ROC and AUC of LinearSVC"
ROC_multi_class(Xtr, ytr, Xtt, ytt, clf_svc)

PR Curves and Area Under the Curve PR (AUC-PR)¶
# importing the required module
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
def PR_multi_class(Xtr, ytr, Xtt, ytt, clf):
classes = [0,1, 2, 3, 4]
# Binarize the output
ytr = label_binarize(ytr, classes=classes)
n_classes = ytr.shape[1]
# Learn to predict each class against the other
classifier = OneVsRestClassifier(clf)
classifier.fit(Xtr, ytr)
if (clf == clf_svc):
y_pred_score = classifier.decision_function(Xtt)
else:
y_pred_score = classifier.predict_proba(Xtt)
ytt = label_binarize(ytt, classes=classes)
# Compute Precision-Recall and plot curve
precision = dict()
recall = dict()
average_precision = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(ytt[:, i], y_pred_score[:, i])
average_precision[i] = average_precision_score(ytt[:, i], y_pred_score[:, i])
for i in range(n_classes):
plt.plot(recall[i], precision[i], label='PR curve of class {0} (area = {1:0.2f})'
''.format(i+1, average_precision[i]))
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall curve of multi-class')
plt.legend(loc="lower right")
plt.show()
# PR curve of MultinomialNB
print "PR and AUC of MultinomialNB"
PR_multi_class(Xtr, ytr, Xtt, ytt, clf_MNB)

# PR curve of KNeighborsClassifier
print "PR and AUC of KNN"
PR_multi_class(Xtr, ytr, Xtt, ytt, clf_knn)

# PR curve of LinearSVC
print "PR and AUC of LinearSVC"
PR_multi_class(Xtr, ytr, Xtt, ytt, clf_svc)

Benchmarking of Different Classifiers¶
Diagram of Benchmarking of different Classifiers:
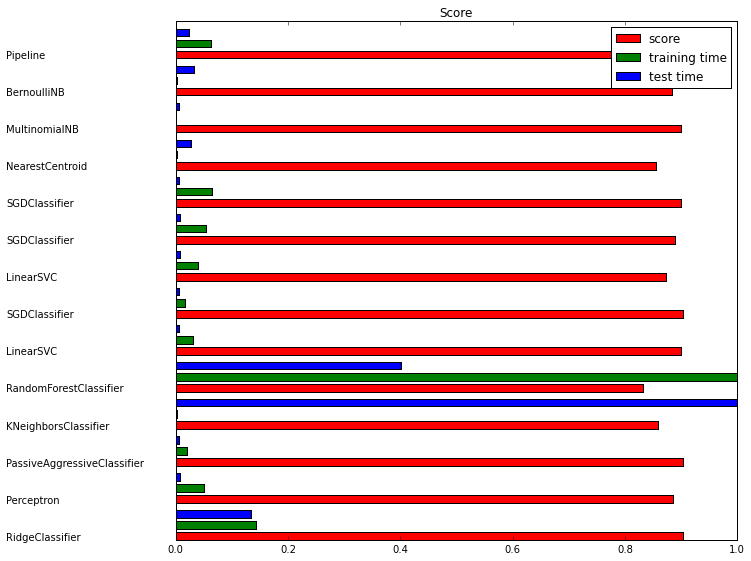
References¶
- https://en.wikipedia.org/wiki/Machine_learning
- http://scikit-learn.org/stable/modules/svm.html
- http://scikit-learn.org/stable/tutorial/basic/tutorial.html
- http://scikitlearn.org/stable/modules/grid_search.html
- http://scikit-learn.org/stable/datasets/twenty_newsgroups.html
- http://scikit-learn.org/stable/auto_examples/text/document_classification_20newsgroups.html#example-text-document-classification-20newsgroups-py
- http://scikit-learn.org/stable/auto_examples/model_selection/grid_search_text_feature_extraction.html#example-model-selection-grid-search-text-feature-extraction-py
- https://en.wikipedia.org/wiki/Sensitivity_and_specificity
- https://en.wikipedia.org/wiki/Sensitivity_and_specificity
- http://scikitlearn.org/stable/modules/generated/sklearn.metrics.roc_curve.html
- http://scikitlearn.org/stable/auto_examples/model_selection/plot_roc.html#example-model-selection-plotroc-py
- http://scikitlearn.org/stable/model_selection.html